
ANSIやUnicodeのような文字エンコードとは何ですか?また、それらはどのように異なりますか?
公開: 2022-01-29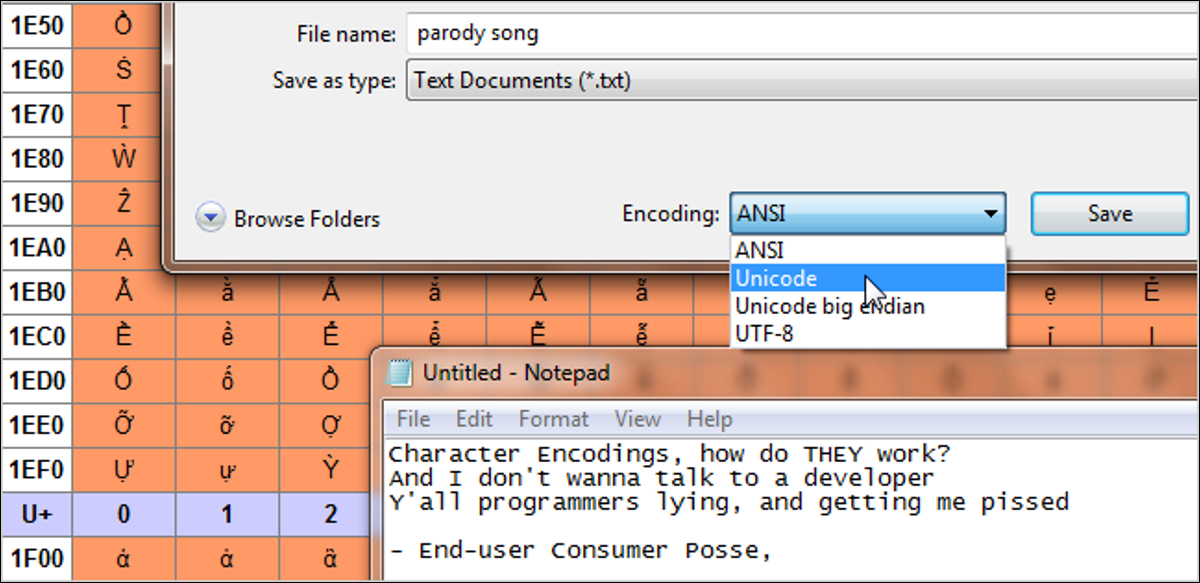
ASCII、UTF-8、ISO-8859…これらの奇妙なモニカが浮かんでいるのを見たことがあるかもしれませんが、実際にはどういう意味ですか? 文字エンコードとは何か、これらの頭字語が画面に表示されるプレーンテキストとどのように関連しているかを説明するときに読んでください。
基本的なビルディングブロック
書き言葉について話すとき、私たちは文字が単語の構成要素であり、それが文や段落などを構成することについて話します。 文字は音を表す記号です。 あなたが言語について話すとき、あなたはある種の意味を形成するために一緒になる音のグループについて話している。 各言語システムには、それらの意味を管理する一連の複雑なルールと定義があります。 あなたが単語を持っているなら、それがどの言語から来ているのかを知らず、その言語を話す他の人と一緒にそれを使わない限り、それは役に立たない。
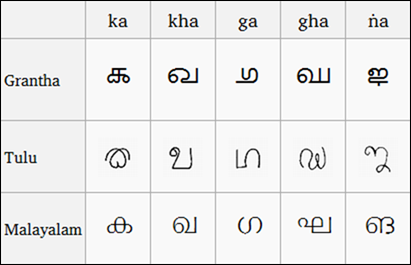
(グランタ文字、トゥル語、マラヤーラム文字の比較、ウィキペディアからの画像)
コンピュータの世界では、「キャラクター」という用語を使用します。 文字は、特定のパラメータによって定義される一種の抽象的な概念ですが、意味の基本単位です。 ラテン語の「A」はギリシャ語の「alpha」やアラビア語の「alif」と同じではありません。コンテキストが異なり、言語が異なり、発音もわずかに異なるため、文字が異なると言えます。 文字の視覚的表現は「グリフ」と呼ばれ、さまざまなグリフのセットはフォントと呼ばれます。 文字のグループは、「セット」または「レパートリー」に属します。
段落を入力してフォントを変更すると、文字の音声値は変更されず、文字の外観も変更されます。 それは単なる見た目です(しかし重要ではありません!)。 古代エジプト語や中国語などの一部の言語には、表意文字があります。 これらは音ではなくアイデア全体を表しており、発音は時間や距離によって変化する可能性があります。 ある文字を別の文字に置き換えると、アイデアを置き換えることになります。 文字を変更するだけでなく、表意文字を変更します。
文字コード

(ウィキペディアからの画像)
キーボードで何かを入力したり、ファイルを読み込んだりするとき、コンピューターはどのようにして何を表示するかを認識しますか? それが文字エンコードの目的です。 コンピューター上のテキストは実際には文字ではなく、一連のペアの英数字の値です。 文字エンコードは、正書法がどの音がどの文字に対応するかを指示するのと同じように、値がどの文字に対応するかについてのキーとして機能します。 モールス信号は一種の文字エンコードです。 ビープ音などの長い単位と短い単位のグループがどのように文字を表すかを説明します。 モールス信号では、文字は英語の文字、数字、およびピリオドです。 文字、数字、アクセント記号、句読点、国際記号などに変換される多くのコンピュータ文字エンコーディングがあります。
このトピックでは、「コードページ」という用語もよく使用されます。 これらは基本的に、特定の企業で使用されている文字エンコードであり、多くの場合、わずかな変更が加えられています。 たとえば、Windows 1252コードページ(以前はANSI 1252と呼ばれていました)は、ISO-8859-1の修正された形式です。 これらは主に、同じシステムに固有の標準および変更された文字エンコードを参照するための内部システムとして使用されます。 初期の頃は、コンピューターが相互に通信していなかったため、文字エンコードはそれほど重要ではありませんでした。 インターネットが目立つようになり、ネットワーキングが一般的になっているため、私たちが気付かないうちに、インターネットは私たちの日常生活においてますます重要になっています。
多くの異なるタイプ

(サラソシアックからの画像)
そこにはたくさんの異なる文字エンコーディングがあり、それにはたくさんの理由があります。 どの文字エンコードを使用するかは、ニーズによって異なります。 ロシア語で通信する場合は、キリル文字を適切にサポートする文字エンコードを使用するのが理にかなっています。 韓国語でコミュニケーションをとるなら、ハングルと漢字をうまく表現したものが必要になります。 あなたが数学者なら、ギリシャ語とラテン語のグリフだけでなく、すべての科学的および数学的な記号がうまく表現されているものが必要です。 あなたがいたずら好きなら、多分あなたは逆さまのテキストから利益を得るでしょう。 また、これらすべての種類のドキュメントを特定の人が閲覧できるようにする場合は、非常に一般的で簡単にアクセスできるエンコーディングが必要です。
より一般的なもののいくつかを見てみましょう。

(ASCIIテーブルの抜粋、asciitable.comからの画像)

- ASCII –情報交換のためのアメリカ標準コードは古い文字エンコーディングの1つです。 もともとは電信コードに基づいて考案され、時間の経過とともに進化して、より多くの記号と、現在は古くなった印刷されていない制御文字が含まれるようになりました。 アクセント付き文字のないラテンアルファベットに限定されているため、現代のシステムではおそらく基本的なものです。 その7ビットエンコーディングでは128文字しか使用できないため、世界中でいくつかの非公式のバリアントが使用されています。
- ISO-8859 –国際標準化機構で最も広く使用されている文字エンコードのグループは番号8859です。特定の各エンコードは番号で示され、多くの場合、説明的なモニカが前に付けられます。たとえば、ISO-8859-3(Latin-3)、ISO- 8859-6(ラテン/アラビア語)。 これはASCIIのスーパーセットです。つまり、エンコーディングの最初の128値はASCIIと同じです。 ただし、8ビットで256文字を使用できるため、そこから構築され、さまざまな基準のセットに焦点を当てた特定のエンコーディングを使用して、はるかに幅広い文字配列が含まれます。 Latin-1にはアクセント記号付きの文字と記号が多数含まれていましたが、後でユーロ記号などの更新されたグリフを含むLatin-9と呼ばれる改訂されたセットに置き換えられました。

(unicode.orgからのチベット文字、Unicode v4の抜粋)
- Unicode –このエンコーディング標準は普遍性を目的としています。 現在、いくつかのブロックに編成された93のスクリプトが含まれており、さらに多くのスクリプトが作業中です。 Unicodeは、グリフを直接コーディングする代わりに、各値がさらに「コードポイント」に送られるという点で、他の文字セットとは動作が異なります。 これらは文字に対応する16進値ですが、グリフ自体はWebブラウザーなどのプログラムによって切り離された方法で提供されます。 これらのコードポイントは、一般的に次のように表されます:U + 0040(これは「@」に変換されます)。 Unicode標準での特定のエンコーディングはUTF-8とUTF-16です。 UTF-8は、ASCIIとの最大の互換性を可能にしようとします。 これは8ビットですが、置換メカニズムと文字ごとの値の複数のペアを介してすべての文字を許可します。 UTF-16は、標準とのより完全な16ビット互換性のために完全なASCII互換性を捨てます。
- ISO-10646 –これは実際のエンコーディングではなく、ISOによって標準化されたUnicodeの文字セットにすぎません。 HTMLで使用される文字レパートリーであるため、これは最も重要です。 Unicodeによって提供される、左から右へのスクリプトと一緒に照合と右から左へのスクリプトを可能にする、より高度な関数のいくつかが欠落しています。 それでも、さまざまなスクリプトを使用でき、ブラウザがグリフを解釈できるため、インターネットでの使用に非常に適しています。 これにより、ローカリゼーションがいくらか簡単になります。
どのエンコーディングを使用する必要がありますか?
ええと、ASCIIはほとんどの英語話者のために働きますが、他の多くのためには働きません。 多くの場合、ほとんどの西ヨーロッパ言語で機能するISO-8859-1が表示されます。 ISO-8859の他のバージョンは、キリル文字、アラビア語、ギリシャ語、またはその他の特定のスクリプトで機能します。 ただし、同じドキュメントまたは同じWebページに複数のスクリプトを表示する場合は、UTF-8を使用すると互換性が大幅に向上します。 また、適切な句読点、数学記号、または正方形やチェックボックスなどのすぐに使える文字を使用する人にも非常に効果的です。

(1つのドキュメントに複数の言語、gujaratsamachar.comのスクリーンショット)
ただし、各セットには欠点があります。 ASCIIは句読点が制限されているため、活字で正しく編集するには信じられないほどうまく機能しません。 Wordからコピー/貼り付けを入力して、グリフの奇妙な組み合わせを作成したことがありますか? これがISO-8859の欠点であり、より正確には、OS固有のコードページとの相互運用性が想定されています(私たちはあなた、マイクロソフトを見ています!)。 UTF-8の主な欠点は、アプリケーションの編集と公開が適切にサポートされていないことです。 もう1つの問題は、ブラウザがUTF-8でエンコードされた文字のバイト順マークを解釈せず、表示するだけである場合が多いことです。 これにより、不要なグリフが表示されます。 そしてもちろん、あるエンコーディングを宣言し、Webページで適切に宣言/参照せずに別の文字を使用すると、ブラウザがそれらを正しくレンダリングしたり、検索エンジンがそれらを適切にインデックス付けしたりすることが困難になります。
自分の文書や原稿などには、仕事を遂行するために必要なものを何でも使用できます。 Webに関する限り、ほとんどの人がバイト順マークを使用しないUTF-8バージョンの使用に同意しているようですが、それは完全に一致しているわけではありません。 ご覧のとおり、各文字エンコードには独自の用途、コンテキスト、長所と短所があります。 エンドユーザーとしては、おそらくこれに対処する必要はありませんが、必要に応じて、さらに一歩前進することができます。