
Ce sunt codificările de caractere precum ANSI și Unicode și cum diferă?
Publicat: 2022-01-29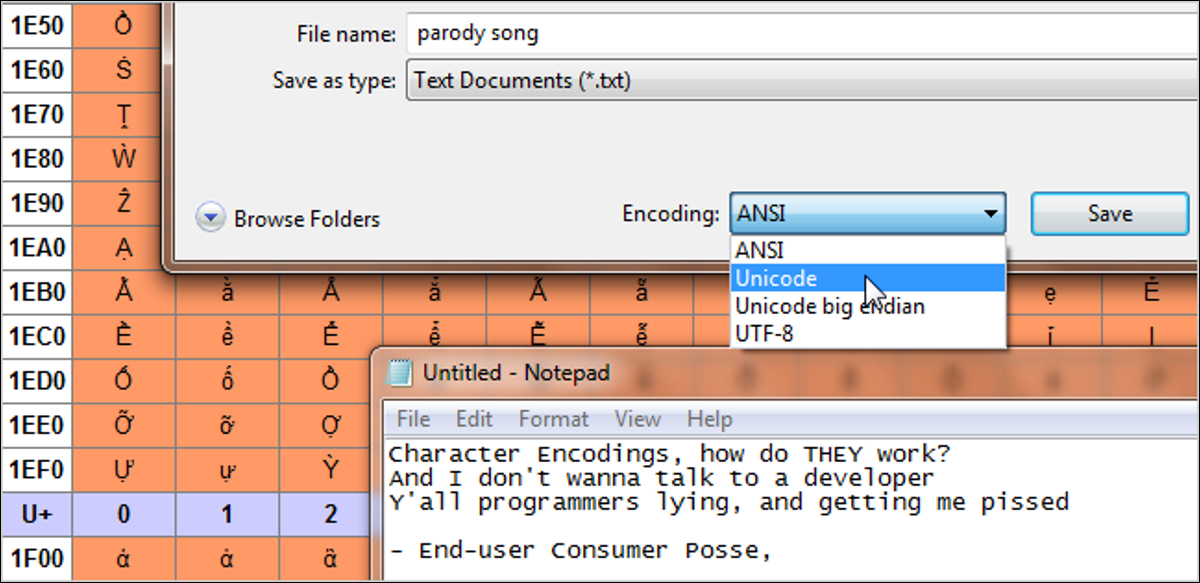
ASCII, UTF-8, ISO-8859... Poate că ați văzut aceste nume ciudate plutind, dar ce înseamnă ele de fapt? Citiți în continuare în timp ce explicăm ce este codificarea caracterelor și cum se leagă aceste acronime cu textul simplu pe care îl vedem pe ecran.
Blocuri fundamentale
Când vorbim despre limbajul scris, vorbim despre literele care sunt elementele de bază ale cuvintelor, care apoi construiesc propoziții, paragrafe și așa mai departe. Literele sunt simboluri care reprezintă sunete. Când vorbești despre limbaj, vorbești despre grupuri de sunete care se unesc pentru a forma un fel de semnificație. Fiecare sistem lingvistic are un set complex de reguli și definiții care guvernează acele semnificații. Dacă ai un cuvânt, este inutil dacă nu știi din ce limbă este și îl folosești cu alții care vorbesc acea limbă.
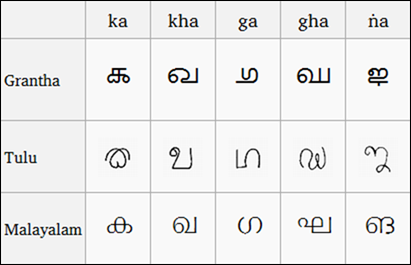
(Comparație între scripturile Grantha, Tulu și Malayalam, imagine de pe Wikipedia)
În lumea computerelor, folosim termenul „personaj”. Un personaj este un fel de concept abstract, definit de parametri specifici, dar este unitatea fundamentală a sensului. „A” latin nu este același cu un „alfa” grecesc sau cu un „alif” arab pentru că au contexte diferite – sunt din limbi diferite și au pronunții ușor diferite – așa că putem spune că sunt caractere diferite. Reprezentarea vizuală a unui caracter se numește „glif” și diferite seturi de glife sunt numite fonturi. Grupurile de personaje aparțin unui „set” sau unui „repertoriu”.
Când introduci un paragraf și schimbi fontul, nu schimbi valorile fonetice ale literelor, schimbi felul în care arată. Este doar cosmetic (dar nu lipsit de importanță!). Unele limbi, cum ar fi egipteana antică și chineza, au ideograme; acestea reprezintă idei întregi în loc de sunete, iar pronunțiile lor pot varia în timp și distanță. Dacă înlocuiți un personaj cu altul, înlocuiți o idee. Este mai mult decât schimbarea literelor, este schimbarea unei ideograme.
Codificarea caracterelor

(Imagine de pe Wikipedia)
Când tastați ceva pe tastatură sau încărcați un fișier, de unde știe computerul ce să afișeze? Pentru asta este codarea caracterelor. Textul de pe computer nu este de fapt litere, este o serie de valori alfanumerice pereche. Codificarea caracterelor acționează ca o cheie pentru care valori corespund caracterelor, la fel ca ortografia dictează ce sunete corespund cărora literele. Codul Morse este un fel de codificare a caracterelor. Acesta explică modul în care grupurile de unități lungi și scurte, cum ar fi bipurile, reprezintă caractere. În codul Morse, caracterele sunt doar litere, cifre și puncte în engleză. Există multe codificări de caractere de computer care se traduc în litere, cifre, semne de accent, semne de punctuație, simboluri internaționale și așa mai departe.
Adesea pe această temă este folosit și termenul „pagini de cod”. Ele sunt, în esență, codificări de caractere așa cum sunt utilizate de anumite companii, adesea cu ușoare modificări. De exemplu, pagina de cod Windows 1252 (cunoscută anterior ca ANSI 1252) este o formă modificată a ISO-8859-1. Ele sunt utilizate în principal ca sistem intern pentru a se referi la codificări standard și modificate de caractere care sunt specifice acelorași sisteme. La început, codificarea caracterelor nu a fost atât de importantă, deoarece computerele nu comunicau între ele. Având în vedere că internetul devine proeminent și crearea de rețele fiind o întâmplare obișnuită, a devenit din ce în ce mai importantă în viața noastră de zi cu zi, fără ca noi să ne dăm seama.
Multe tipuri diferite

(Imagine de la sarah sosiak)
Există o mulțime de codificări diferite de caractere și există o mulțime de motive pentru asta. Ce codificare de caractere alegeți să utilizați depinde de nevoile dvs. Dacă comunicați în rusă, este logic să utilizați o codificare a caracterelor care acceptă bine chirilica. Dacă comunici în coreeană, atunci îți vei dori ceva care să reprezinte bine Hangul și Hanja. Dacă ești matematician, atunci vrei ceva care să aibă toate simbolurile științifice și matematice bine reprezentate, precum și glifele grecești și latine. Dacă ești un fars, poate ai beneficia de textul cu susul în jos. Și, dacă doriți ca toate aceste tipuri de documente să fie vizualizate de orice persoană dată, doriți o codificare destul de comună și ușor accesibilă.
Să aruncăm o privire la unele dintre cele mai comune.

(Fragment din tabelul ASCII, imagine de pe asciitable.com)
- ASCII – Codul standard american pentru schimbul de informații este una dintre cele mai vechi codificări de caractere. A fost conceput inițial pe baza codurilor telegrafice și a evoluat de-a lungul timpului pentru a include mai multe simboluri și unele caractere de control neimprimate învechite. Probabil că este la fel de simplu pe cât puteți obține în ceea ce privește sistemele moderne, deoarece este limitat la alfabetul latin fără caractere accentuate. Codarea sa pe 7 biți permite doar 128 de caractere, motiv pentru care există mai multe variante neoficiale utilizate în întreaga lume.
- ISO-8859 – Cel mai utilizat grup de codificări de caractere de către Organizația Internațională pentru Standardizare este numărul 8859. Fiecare codificare specifică este desemnată printr-un număr, adesea prefixat de un nume descriptiv, de exemplu ISO-8859-3 (Latin-3), ISO- 8859-6 (latină/arabă). Este un superset de ASCII, ceea ce înseamnă că primele 128 de valori din codificare sunt aceleași cu ASCII. Cu toate acestea, este pe 8 biți și permite 256 de caractere, așa că se construiește de acolo și include o gamă mult mai largă de caractere, fiecare codificare specifică concentrându-se pe un set diferit de criterii. Latin-1 a inclus o grămadă de litere și simboluri accentuate, dar ulterior a fost înlocuit cu un set revizuit numit Latin-9, care include glife actualizate precum simbolul euro.


(Fragment din scriptul tibetan, Unicode v4, de pe unicode.org)
- Unicode – Acest standard de codificare vizează universalitatea. În prezent, include 93 de scripturi organizate în mai multe blocuri, cu multe altele în lucru. Unicode funcționează diferit față de alte seturi de caractere prin aceea că, în loc să codifice direct pentru un glif, fiecare valoare este direcționată mai departe către un „punct de cod”. Acestea sunt valori hexazecimale care corespund caracterelor, dar glifele în sine sunt furnizate într-un mod detașat de program, cum ar fi browserul dvs. web. Aceste puncte de cod sunt descrise în mod obișnuit după cum urmează: U+0040 (care se traduce prin „@”). Codificările specifice conform standardului Unicode sunt UTF-8 și UTF-16. UTF-8 încearcă să permită compatibilitate maximă cu ASCII. Este pe 8 biți, dar permite toate caracterele printr-un mecanism de înlocuire și mai multe perechi de valori per caracter. UTF-16 renunță la compatibilitatea perfectă ASCII pentru o compatibilitate mai completă pe 16 biți cu standardul.
- ISO-10646 – Aceasta nu este o codificare reală, ci doar un set de caractere Unicode care a fost standardizat de ISO. Este important în principal pentru că este repertoriul de caractere folosit de HTML. Unele dintre funcțiile mai avansate oferite de Unicode care permit colarearea și scriptarea de la dreapta la stânga alături de scripturi de la stânga la dreapta lipsesc. Cu toate acestea, funcționează foarte bine pentru utilizarea pe internet, deoarece permite utilizarea unei game largi de scripturi și permite browserului să interpreteze glifele. Acest lucru face localizarea oarecum mai ușoară.
Ce codificare ar trebui să folosesc?
Ei bine, ASCII funcționează pentru majoritatea vorbitorilor de engleză, dar nu pentru multe altele. Mai des veți vedea ISO-8859-1, care funcționează pentru majoritatea limbilor vest-europene. Celelalte versiuni ale ISO-8859 funcționează pentru scripturi chirilice, arabă, greacă sau alte scripturi specifice. Cu toate acestea, dacă doriți să afișați mai multe scripturi în același document sau pe aceeași pagină web, UTF-8 permite o compatibilitate mult mai bună. De asemenea, funcționează foarte bine pentru persoanele care folosesc semne de punctuație adecvate, simboluri matematice sau caractere care nu sunt disponibile, cum ar fi pătratele și casetele de selectare.

(Mai multe limbi într-un singur document, captură de ecran de pe gujaratsamachar.com)
Cu toate acestea, fiecare set are dezavantaje. ASCII este limitat în semnele de punctuație, așa că nu funcționează incredibil de bine pentru editări corecte tipografic. Tastați vreodată copy/paste din Word doar pentru a avea o combinație ciudată de glife? Acesta este dezavantajul ISO-8859, sau mai corect, presupusa sa interoperabilitate cu paginile de cod specifice sistemului de operare (ne uităm la TU, Microsoft!). Dezavantajul major al UTF-8 este lipsa suportului adecvat în editarea și publicarea aplicațiilor. O altă problemă este că de multe ori browserele nu interpretează și doar afișează marcajul ordinii octeților unui caracter codificat UTF-8. Acest lucru duce la afișarea glifelor nedorite. Și, bineînțeles, declararea unei codificări și utilizarea caracterelor dintr-o alta fără declararea/referirea corectă a acestora pe o pagină web face dificil pentru browsere să le redeze corect și pentru motoarele de căutare să le indexeze corespunzător.
Pentru propriile documente, manuscrise și așa mai departe, puteți folosi orice aveți nevoie pentru a finaliza treaba. Totuși, în ceea ce privește internetul, se pare că majoritatea oamenilor sunt de acord cu utilizarea unei versiuni UTF-8 care nu folosește un semn de ordine a octetilor, dar asta nu este în totalitate unanim. După cum puteți vedea, fiecare codare de caractere are propria sa utilizare, context și puncte forte și puncte slabe. În calitate de utilizator final, probabil că nu va trebui să vă ocupați de acest lucru, dar acum puteți face un pas suplimentar înainte dacă doriți.