
什么是 ANSI 和 Unicode 等字符编码,它们有何不同?
已发表: 2022-01-29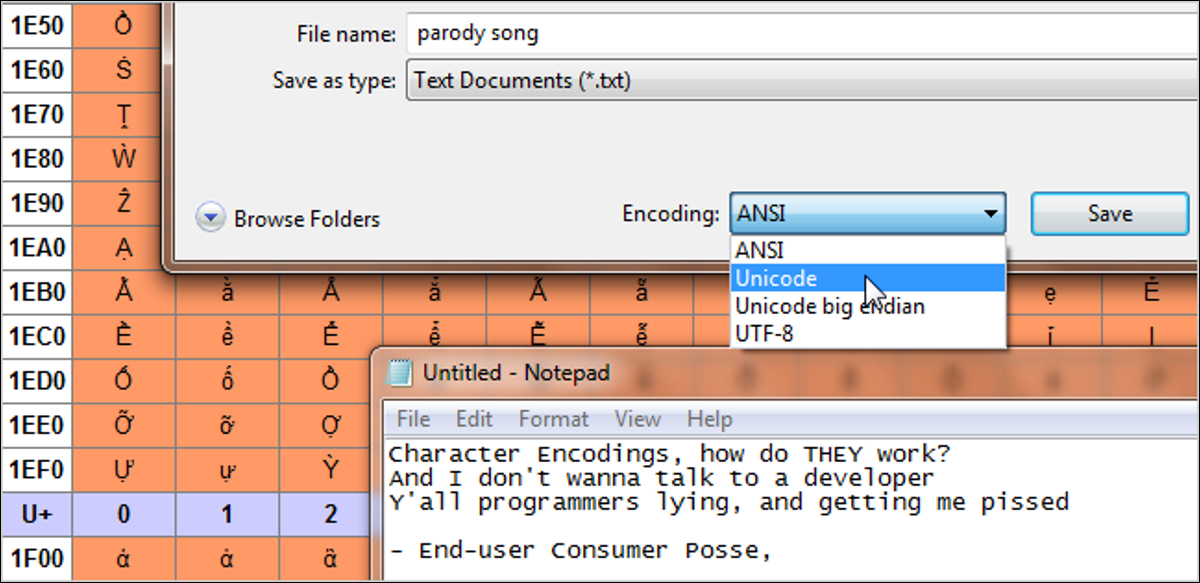
ASCII、UTF-8、ISO-8859……您可能已经看到了这些奇怪的名字,但它们的真正含义是什么? 在我们解释什么是字符编码以及这些首字母缩略词与我们在屏幕上看到的纯文本之间的关系时,请继续阅读。
基本构建块
当我们谈论书面语言时,我们谈论的是字母是单词的组成部分,然后构成句子、段落等。 字母是代表声音的符号。 当您谈论语言时,您是在谈论组合在一起形成某种意义的声音组。 每个语言系统都有一套复杂的规则和定义来管理这些含义。 如果你有一个词,除非你知道它来自什么语言并且你和其他说这种语言的人一起使用它,否则它是没有用的。
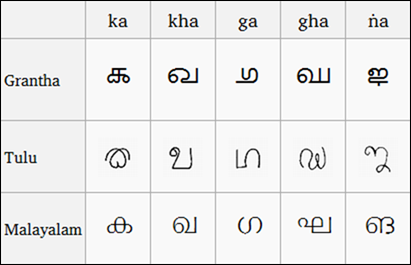
(Grantha、Tulu 和马拉雅拉姆语脚本的比较,图片来自维基百科)
在计算机世界中,我们使用术语“字符”。 字符是一种抽象概念,由特定参数定义,但它是意义的基本单位。 拉丁语“A”与希腊语“alpha”或阿拉伯语“alif”不同,因为它们有不同的上下文——它们来自不同的语言并且发音略有不同——所以我们可以说它们是不同的字符。 字符的视觉表示称为“字形”,不同的字形集称为字体。 字符组属于“集合”或“曲目”。
当你输入一个段落并改变字体时,你并没有改变字母的音值,你改变了它们的外观。 这只是化妆品(但并非不重要!)。 有些语言,如古埃及语和汉语,有表意文字; 这些代表完整的想法而不是声音,并且它们的发音会随着时间和距离而变化。 如果你用一个字符替换另一个字符,你就是在替换一个想法。 这不仅仅是改变字母,而是改变表意文字。
字符编码

(图片来自维基百科)
当您在键盘上键入内容或加载文件时,计算机如何知道要显示什么? 这就是字符编码的用途。 您计算机上的文本实际上不是字母,而是一系列成对的字母数字值。 字符编码充当其值对应于哪些字符的键,就像正字法如何指示哪些声音对应于哪些字母一样。 摩尔斯电码是一种字符编码。 它解释了诸如哔哔声之类的长短单位组如何表示字符。 在摩尔斯电码中,字符只是英文字母、数字和句号。 有许多计算机字符编码可以翻译成字母、数字、重音符号、标点符号、国际符号等。
通常在这个主题上,也使用术语“代码页”。 它们本质上是特定公司使用的字符编码,通常稍作修改。 例如,Windows 1252 代码页(以前称为 ANSI 1252)是 ISO-8859-1 的修改形式。 它们主要用作内部系统来指代特定于相同系统的标准和修改的字符编码。 早期,字符编码并不那么重要,因为计算机之间不能相互通信。 随着互联网的兴起和网络的普及,它在我们的日常生活中变得越来越重要,而我们甚至没有意识到这一点。
许多不同的类型

(图片来自莎拉索西亚克)
那里有很多不同的字符编码,这有很多原因。 您选择使用哪种字符编码取决于您的需求。 如果您使用俄语进行交流,那么使用能够很好地支持西里尔文的字符编码是有意义的。 如果你用韩语交流,那么你会想要能很好地代表韩文和汉字的东西。 如果您是一名数学家,那么您需要能够很好地表示所有科学和数学符号以及希腊语和拉丁语字形的东西。 如果你是个恶作剧者,也许你会从颠倒的文字中受益。 而且,如果您希望任何给定的人都可以查看所有这些类型的文档,那么您需要一种非常常见且易于访问的编码。
让我们来看看一些比较常见的。


(ASCII 表摘录,图片来自 asciitable.com)
- ASCII – 美国信息交换标准代码是较旧的字符编码之一。 它最初是基于电报代码设计的,并随着时间的推移而演变为包含更多符号和一些现已过时的非印刷控制字符。 它可能与现代系统一样基本,因为它仅限于没有重音字符的拉丁字母。 它的 7 位编码仅允许 128 个字符,这就是为什么在世界各地使用了几种非官方变体的原因。
- ISO-8859 – 国际标准化组织使用最广泛的字符编码组是数字 8859。每个特定的编码都由一个数字指定,通常以一个描述性名称作为前缀,例如 ISO-8859-3 (Latin-3)、ISO- 8859-6(拉丁文/阿拉伯文)。 它是 ASCII 的超集,这意味着编码中的前 128 个值与 ASCII 相同。 然而,它是 8 位的,允许 256 个字符,因此它从那里构建并包含更广泛的字符数组,每个特定的编码都侧重于一组不同的标准。 Latin-1 包括一堆重音字母和符号,但后来被称为 Latin-9 的修订集取代,其中包括更新的字形,如欧元符号。

(摘自藏文,Unicode v4,来自 unicode.org)
- Unicode – 该编码标准旨在实现普遍性。 它目前包括 93 个脚本,这些脚本被组织在几个块中,还有更多正在制作中。 Unicode 与其他字符集的工作方式不同,因为它不是直接对字形进行编码,而是将每个值进一步定向到一个“代码点”。 这些是对应于字符的十六进制值,但字形本身是由程序以分离的方式提供的,例如您的 Web 浏览器。 这些代码点通常描述如下:U+0040(转换为“@”)。 Unicode 标准下的特定编码是 UTF-8 和 UTF-16。 UTF-8 试图最大程度地兼容 ASCII。 它是 8 位的,但通过替换机制和每个字符的多对值允许所有字符。 UTF-16 抛弃了完美的 ASCII 兼容性,以实现与标准的更完整的 16 位兼容性。
- ISO-10646 – 这不是实际的编码,只是 ISO 标准化的 Unicode 字符集。 这很重要,因为它是 HTML 使用的字符库。 缺少 Unicode 提供的一些更高级的功能,这些功能允许整理和从右到左以及从左到右的脚本编写。 尽管如此,它仍然非常适合在 Internet 上使用,因为它允许使用各种脚本并允许浏览器解释字形。 这使得本地化稍微容易一些。
我应该使用什么编码?
好吧,ASCII 适用于大多数说英语的人,但不适用于其他很多。 您会经常看到适用于大多数西欧语言的 ISO-8859-1。 ISO-8859 的其他版本适用于西里尔文、阿拉伯文、希腊文或其他特定文字。 但是,如果您想在同一个文档或同一个网页上显示多个脚本,UTF-8 可以提供更好的兼容性。 它也适用于使用正确标点符号、数学符号或即兴字符(例如正方形和复选框)的人。

(一份文档中的多种语言,gujaratsamachar.com 的屏幕截图)
然而,每组都有缺点。 ASCII 的标点符号受到限制,因此对于印刷正确的编辑来说效果不佳。 曾经从 Word 中输入复制/粘贴只是为了得到一些奇怪的字形组合? 这就是 ISO-8859 的缺点,或者更准确地说,它假定的与特定于操作系统的代码页的互操作性(我们正在寻找你,微软!)。 UTF-8 的主要缺点是在编辑和发布应用程序中缺乏适当的支持。 另一个问题是浏览器通常不解释,只显示 UTF-8 编码字符的字节顺序标记。 这会导致显示不需要的字形。 当然,声明一种编码并使用另一种编码而不在网页上正确声明/引用它们会使浏览器难以正确呈现它们并且搜索引擎难以适当地索引它们。
对于您自己的文档、手稿等,您可以使用完成工作所需的任何内容。 不过,就网络而言,似乎大多数人都同意使用不使用字节顺序标记的 UTF-8 版本,但这并不完全一致。 如您所见,每种字符编码都有其自己的用途、上下文以及优缺点。 作为最终用户,您可能不必处理这个问题,但如果您愿意,现在您可以向前迈出额外的一步。