
Что такое кодировки символов, такие как ANSI и Unicode, и чем они отличаются?
Опубликовано: 2022-01-29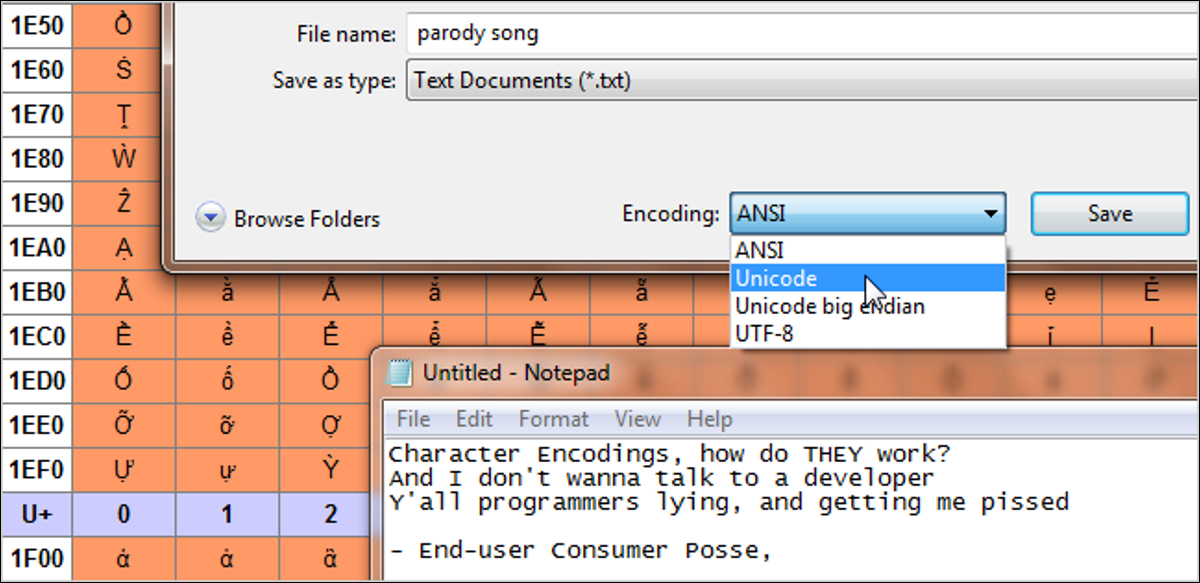
ASCII, UTF-8, ISO-8859… Возможно, вы видели эти странные прозвища, но что они на самом деле означают? Читайте дальше, пока мы объясняем, что такое кодировка символов и как эти аббревиатуры связаны с обычным текстом, который мы видим на экране.
Основные строительные блоки
Когда мы говорим о письменном языке, мы говорим о буквах, являющихся строительными блоками слов, из которых затем строятся предложения, абзацы и так далее. Буквы – это символы, обозначающие звуки. Когда вы говорите о языке, вы имеете в виду группы звуков, которые объединяются, чтобы сформировать какое-то значение. Каждая языковая система имеет сложный набор правил и определений, регулирующих эти значения. Если у вас есть слово, оно бесполезно, если вы не знаете, из какого оно языка, и не используете его с другими, говорящими на этом языке.
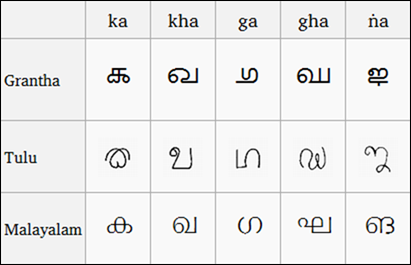
(Сравнение сценариев грантха, тулу и малаялам, изображение из Википедии)
В мире компьютеров мы используем термин «персонаж». Символ — это своего рода абстрактное понятие, определяемое определенными параметрами, но это основная единица значения. Латинское «А» — это не то же самое, что греческое «альфа» или арабское «алиф», потому что они имеют разный контекст — они из разных языков и имеют немного разное произношение — поэтому мы можем сказать, что это разные символы. Визуальное представление символа называется «глиф», а различные наборы глифов называются шрифтами. Группы персонажей принадлежат «набору» или «репертуару».
Когда вы печатаете абзац и меняете шрифт, вы не меняете фонетические значения букв, вы меняете их внешний вид. Это просто косметика (но не маловажная!). В некоторых языках, таких как древнеегипетский и китайский, есть идеограммы; они представляют собой целые идеи, а не звуки, и их произношение может меняться со временем и на расстоянии. Если вы заменяете один символ другим, вы заменяете идею. Это больше, чем просто изменение букв, это изменение идеограммы.
Кодировка символов

(Изображение из Википедии)
Когда вы печатаете что-то на клавиатуре или загружаете файл, как компьютер узнает, что отображать? Вот для чего нужна кодировка символов. Текст на вашем компьютере на самом деле не буквы, а последовательность парных буквенно-цифровых значений. Кодировка символов действует как ключ, для которого значения соответствуют каким символам, подобно тому, как орфография диктует, какие звуки соответствуют каким буквам. Азбука Морзе — это своего рода кодировка символов. Это объясняет, как группы длинных и коротких единиц, таких как гудки, представляют символы. В азбуке Морзе используются только английские буквы, цифры и точки. Существует множество компьютерных кодировок символов, которые преобразуются в буквы, цифры, знаки ударения, знаки препинания, международные символы и так далее.
Часто по этой теме также используется термин «кодовые страницы». По сути, это кодировки символов, используемые конкретными компаниями, часто с небольшими изменениями. Например, кодовая страница Windows 1252 (ранее известная как ANSI 1252) представляет собой модифицированную форму ISO-8859-1. В основном они используются как внутренняя система для обозначения стандартных и модифицированных кодировок символов, характерных для одних и тех же систем. Раньше кодировка символов не была так важна, потому что компьютеры не взаимодействовали друг с другом. По мере того, как Интернет становится все более популярным, а сети становятся обычным явлением, они становятся все более важными в нашей повседневной жизни, даже если мы этого не осознаем.
Много разных типов

(Изображение от Сары Сосиак)
Существует множество различных кодировок символов, и на это есть множество причин. Какую кодировку символов вы решите использовать, зависит от ваших потребностей. Если вы общаетесь на русском языке, имеет смысл использовать кодировку, хорошо поддерживающую кириллицу. Если вы общаетесь на корейском языке, вам понадобится что-то, что хорошо представляет хангыль и ханджа. Если вы математик, то вам нужно что-то, в чем хорошо представлены все научные и математические символы, а также греческие и латинские глифы. Если вы шутник, возможно, вам будет полезен перевернутый текст. И, если вы хотите, чтобы все эти типы документов были просмотрены любым человеком, вам нужна довольно распространенная и легкодоступная кодировка.
Давайте взглянем на некоторые из наиболее распространенных.

(Выдержка из таблицы ASCII, изображение с сайта asciitable.com)
- ASCII — американский стандартный код для обмена информацией — одна из старых кодировок символов. Первоначально он был разработан на основе телеграфных кодов и со временем эволюционировал, чтобы включать больше символов и некоторые устаревшие непечатаемые управляющие символы. Это, вероятно, настолько просто, насколько это возможно с точки зрения современных систем, поскольку оно ограничено латинским алфавитом без символов с диакритическими знаками. Его 7-битная кодировка позволяет использовать только 128 символов, поэтому во всем мире используется несколько неофициальных вариантов.
- ISO-8859 . Наиболее широко используемой группой кодировок символов Международной организации по стандартизации является номер 8859. Каждая конкретная кодировка обозначается числом, часто с префиксом описательного прозвища, например, ISO-8859-3 (Latin-3), ISO- 8859-6 (латиница/арабский). Это надмножество ASCII, означающее, что первые 128 значений в кодировке совпадают с ASCII. Однако он 8-битный и позволяет использовать 256 символов, поэтому он основывается на этом и включает в себя гораздо более широкий набор символов, причем каждая конкретная кодировка ориентирована на другой набор критериев. Latin-1 включал набор букв и символов с акцентом, но позже был заменен пересмотренным набором под названием Latin-9, который включает обновленные глифы, такие как символ евро.


(Отрывок из тибетского письма, Unicode v4, с сайта unicode.org)
- Unicode — этот стандарт кодирования нацелен на универсальность. В настоящее время он включает 93 сценария, организованных в несколько блоков, и многие другие находятся в разработке. Юникод работает иначе, чем другие наборы символов, поскольку вместо прямого кодирования глифа каждое значение направляется дальше к «кодовой точке». Это шестнадцатеричные значения, соответствующие символам, но сами глифы предоставляются программой отдельно, например, вашим веб-браузером. Эти кодовые точки обычно изображаются следующим образом: U+0040 (что переводится как «@»). Конкретными кодировками стандарта Unicode являются UTF-8 и UTF-16. UTF-8 пытается обеспечить максимальную совместимость с ASCII. Он 8-битный, но позволяет использовать все символы с помощью механизма подстановки и нескольких пар значений для каждого символа. UTF-16 отказывается от идеальной совместимости с ASCII для более полной 16-битной совместимости со стандартом.
- ISO-10646 — это не настоящая кодировка, а просто набор символов Unicode, стандартизированный ISO. Это в основном важно, потому что это репертуар символов, используемый HTML. Некоторые из более продвинутых функций, предоставляемых Unicode, которые позволяют выполнять сортировку и писать справа налево наряду со сценариями слева направо, отсутствуют. Тем не менее, он очень хорошо работает для использования в Интернете, поскольку позволяет использовать широкий спектр сценариев и позволяет браузеру интерпретировать глифы. Это несколько упрощает локализацию.
Какую кодировку следует использовать?
Ну, ASCII работает для большинства носителей английского языка, но не для чего-то еще. Чаще вы будете встречать ISO-8859-1, который работает для большинства западноевропейских языков. Другие версии ISO-8859 работают для кириллицы, арабского, греческого и других шрифтов. Однако, если вы хотите отобразить несколько сценариев в одном документе или на одной веб-странице, UTF-8 обеспечивает гораздо лучшую совместимость. Это также очень хорошо работает для людей, которые используют правильную пунктуацию, математические символы или нестандартные символы, такие как квадраты и флажки.

(Несколько языков в одном документе, снимок экрана с сайта gujaratsamachar.com)
Однако у каждого набора есть недостатки. ASCII ограничен в своих знаках препинания, поэтому он не очень хорошо работает для типографически правильных правок. Вы когда-нибудь вводили копирование/вставку из Word только для того, чтобы получить какое-то странное сочетание глифов? Это недостаток ISO-8859, или, точнее, его предполагаемая совместимость с кодовыми страницами, специфичными для ОС (мы смотрим на ВАС, Microsoft!). Основным недостатком UTF-8 является отсутствие надлежащей поддержки в приложениях для редактирования и публикации. Другая проблема заключается в том, что браузеры часто не интерпретируют и просто отображают метку порядка байтов символа в кодировке UTF-8. Это приводит к отображению нежелательных глифов. И, конечно же, объявление одной кодировки и использование символов из другой без правильного объявления/ссылки на них на веб-странице затрудняет их правильное отображение браузерами и поисковыми системами их правильную индексацию.
Для ваших собственных документов, рукописей и т. д. вы можете использовать все, что вам нужно для выполнения работы. Тем не менее, что касается Интернета, похоже, что большинство людей согласны с использованием версии UTF-8, в которой не используется знак порядка байтов, но это не совсем единодушно. Как видите, каждая кодировка символов имеет свое собственное использование, контекст, сильные и слабые стороны. Как конечному пользователю вам, вероятно, не придется с этим сталкиваться, но теперь вы можете сделать дополнительный шаг вперед, если захотите.