
การเข้ารหัสอักขระเช่น ANSI และ Unicode คืออะไรและแตกต่างกันอย่างไร
เผยแพร่แล้ว: 2022-01-29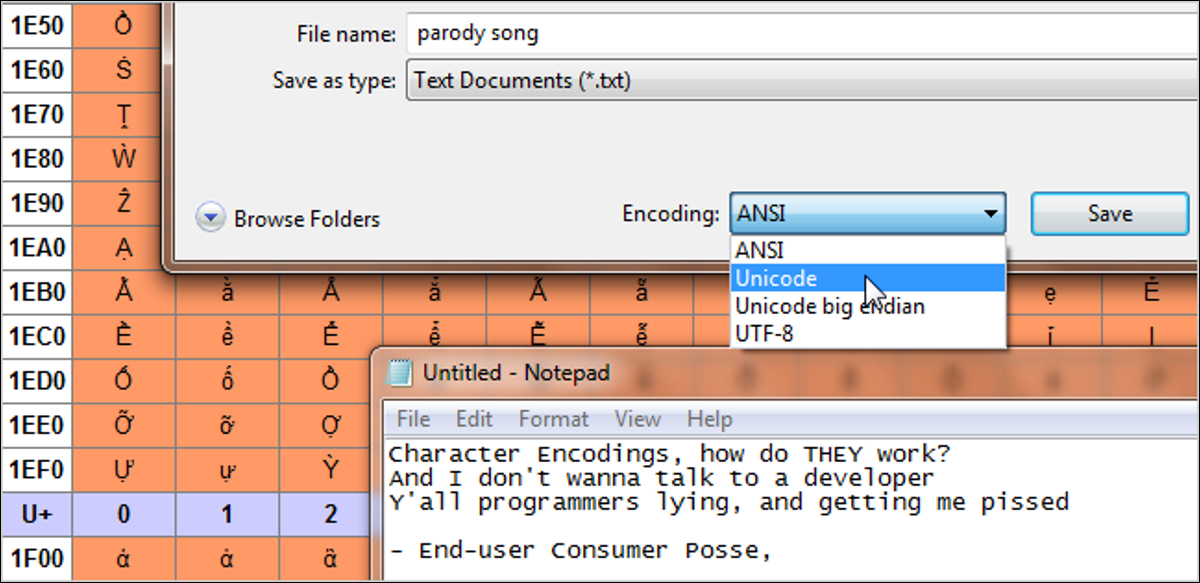
ASCII, UTF-8, ISO-8859… คุณอาจเคยเห็นชื่อเล่นแปลกๆ เหล่านี้ลอยไปมา แต่จริงๆ แล้วพวกมันหมายความว่าอย่างไร อ่านต่อในขณะที่เราอธิบายว่าการเข้ารหัสอักขระคืออะไร และคำย่อเหล่านี้เกี่ยวข้องกับข้อความธรรมดาที่เราเห็นบนหน้าจออย่างไร
การสร้างบล็อคพื้นฐาน
เมื่อเราพูดถึงภาษาเขียน เราพูดถึงตัวอักษรที่เป็นส่วนประกอบสำคัญของคำ ซึ่งจะสร้างประโยค ย่อหน้า และอื่นๆ ตัวอักษรเป็นสัญลักษณ์แทนเสียง เมื่อคุณพูดถึงภาษา คุณกำลังพูดถึงกลุ่มของเสียงที่มารวมกันเพื่อสร้างความหมายบางอย่าง แต่ละระบบภาษามีกฎเกณฑ์และคำจำกัดความที่ซับซ้อนซึ่งควบคุมความหมายเหล่านั้น ถ้าคุณมีคำ มันก็ไม่มีประโยชน์ เว้นแต่คุณจะรู้ว่ามันมาจากภาษาอะไร และคุณใช้มันกับคนอื่นที่พูดภาษานั้น
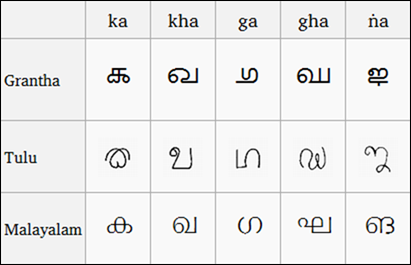
(เปรียบเทียบสคริปต์ Grantha, Tulu และ Malayalam, ภาพจาก Wikipedia)
ในโลกของคอมพิวเตอร์ เราใช้คำว่า "ตัวละคร" ตัวละครเป็นแนวคิดที่เป็นนามธรรม ซึ่งกำหนดโดยพารามิเตอร์เฉพาะ แต่เป็นหน่วยพื้นฐานของความหมาย ภาษาละติน 'A' ไม่เหมือนกับ 'อัลฟา' ของกรีกหรือ 'อาลิฟ' ภาษาอาหรับ เนื่องจากมีบริบทต่างกัน - มาจากภาษาต่างๆ และมีการออกเสียงต่างกันเล็กน้อย - ดังนั้นเราจึงสามารถพูดได้ว่าเป็นอักขระที่แตกต่างกัน การแสดงภาพของตัวละครเรียกว่า "ร่ายมนตร์" และชุดของร่ายมนตร์ที่แตกต่างกันจะเรียกว่าฟอนต์ กลุ่มของตัวละครเป็นของ "ชุด" หรือ "ละคร"
เมื่อคุณพิมพ์ย่อหน้าและเปลี่ยนฟอนต์ คุณไม่ได้เปลี่ยนค่าการออกเสียงของตัวอักษร แต่คุณกำลังเปลี่ยนรูปลักษณ์ เป็นเพียงเครื่องสำอาง (แต่ไม่สำคัญ!) บางภาษา เช่น อียิปต์โบราณและจีน มีแนวคิด สิ่งเหล่านี้เป็นตัวแทนของความคิดทั้งหมดแทนที่จะเป็นเสียง และการออกเสียงอาจแตกต่างกันไปตามกาลเวลาและระยะทาง หากคุณเปลี่ยนอักขระตัวหนึ่งเป็นอีกตัวหนึ่ง แสดงว่าคุณกำลังแทนที่แนวคิด เป็นมากกว่าการเปลี่ยนตัวอักษร มันคือการเปลี่ยนอุดมการณ์
การเข้ารหัสอักขระ

(รูปภาพจากวิกิพีเดีย)
เมื่อคุณพิมพ์บางอย่างบนแป้นพิมพ์ หรือโหลดไฟล์ คอมพิวเตอร์จะทราบได้อย่างไรว่าจะแสดงอะไร นั่นคือสิ่งที่การเข้ารหัสอักขระมีไว้สำหรับ ข้อความในคอมพิวเตอร์ของคุณไม่ใช่ตัวอักษร แต่เป็นชุดของค่าที่เป็นตัวอักษรและตัวเลขคละกัน การเข้ารหัสอักขระทำหน้าที่เป็นกุญแจสำหรับค่าที่สอดคล้องกับอักขระใด เหมือนกับที่การอักขรวิธีกำหนดเสียงที่สอดคล้องกับตัวอักษรใด รหัสมอร์สเป็นประเภทของการเข้ารหัสอักขระ โดยจะอธิบายว่ากลุ่มของหน่วยยาวและสั้น เช่น เสียงบี๊บแสดงถึงอักขระอย่างไร ในรหัสมอร์ส อักขระเป็นเพียงตัวอักษรภาษาอังกฤษ ตัวเลข และจุดเต็ม มีการเข้ารหัสอักขระคอมพิวเตอร์จำนวนมากซึ่งแปลเป็นตัวอักษร ตัวเลข เครื่องหมายเน้นเสียง เครื่องหมายวรรคตอน สัญลักษณ์สากล และอื่นๆ
บ่อยครั้งในหัวข้อนี้ คำว่า "หน้าโค้ด" ก็ถูกใช้เช่นกัน โดยพื้นฐานแล้วมันคือการเข้ารหัสอักขระที่ใช้โดยบริษัทเฉพาะ มักจะมีการดัดแปลงเล็กน้อย ตัวอย่างเช่น โค้ดเพจ Windows 1252 (เดิมเรียกว่า ANSI 1252) เป็นรูปแบบที่แก้ไขของ ISO-8859-1 ส่วนใหญ่จะใช้เป็นระบบภายในเพื่ออ้างถึงการเข้ารหัสอักขระมาตรฐานและแบบแก้ไขที่เจาะจงสำหรับระบบเดียวกัน ในช่วงแรกๆ การเข้ารหัสอักขระไม่สำคัญนักเพราะคอมพิวเตอร์ไม่ได้สื่อสารกัน ด้วยอินเทอร์เน็ตที่เพิ่มขึ้นสู่ความโดดเด่นและการสร้างเครือข่ายเป็นสิ่งที่เกิดขึ้นทั่วไป อินเทอร์เน็ตจึงมีความสำคัญมากขึ้นเรื่อยๆ ในชีวิตประจำวันของเราโดยที่เราไม่รู้ตัว
หลายประเภท

(ภาพจาก sarah sosiak)
มีการเข้ารหัสอักขระที่แตกต่างกันมากมาย และมีเหตุผลมากมายสำหรับสิ่งนั้น การเข้ารหัสอักขระใดที่คุณเลือกใช้ขึ้นอยู่กับความต้องการของคุณ หากคุณสื่อสารเป็นภาษารัสเซีย การใช้การเข้ารหัสอักขระที่สนับสนุนอักษรซีริลลิกก็เป็นเรื่องที่สมเหตุสมผล หากคุณสื่อสารเป็นภาษาเกาหลี คุณจะต้องการบางสิ่งที่แสดงถึงฮันกึลและฮันจาได้ดี หากคุณเป็นนักคณิตศาสตร์ คุณต้องการบางสิ่งที่มีสัญลักษณ์ทางวิทยาศาสตร์และคณิตศาสตร์ทั้งหมดแสดงได้ดี เช่นเดียวกับร่ายมนตร์กรีกและละติน หากคุณเป็นคนพิเรนทร์ บางทีคุณอาจจะได้ประโยชน์จากข้อความกลับหัว และถ้าคุณต้องการให้บุคคลใดก็ตามดูเอกสารประเภทนั้นได้ คุณต้องการการเข้ารหัสที่ค่อนข้างธรรมดาและเข้าถึงได้ง่าย
ลองมาดูที่บางส่วนที่พบบ่อยมากขึ้น

(ข้อความที่ตัดตอนมาจากตาราง ASCII ภาพจาก asciitable.com)
- ASCII – The American Standard Code for Information Interchange เป็นหนึ่งในการเข้ารหัสอักขระที่เก่ากว่า เดิมทีได้รับการออกแบบโดยใช้รหัสโทรเลขและพัฒนาตลอดเวลาเพื่อรวมสัญลักษณ์เพิ่มเติมและอักขระควบคุมที่ไม่ได้พิมพ์ที่ล้าสมัยในขณะนี้ อาจเป็นพื้นฐานเท่าที่คุณจะทำได้ในแง่ของระบบสมัยใหม่ เนื่องจากจำกัดเฉพาะอักษรละตินที่ไม่มีอักขระเน้นเสียง การเข้ารหัสแบบ 7 บิตอนุญาตให้ใช้อักขระได้เพียง 128 ตัว ซึ่งเป็นเหตุให้มีรูปแบบที่ไม่เป็นทางการหลายแบบทั่วโลก
- ISO-8859 – กลุ่มการเข้ารหัสอักขระที่ใช้กันอย่างแพร่หลายมากที่สุดขององค์การระหว่างประเทศเพื่อการมาตรฐานคือหมายเลข 8859 การเข้ารหัสเฉพาะแต่ละรายการถูกกำหนดด้วยตัวเลข มักนำหน้าด้วยชื่อเล่นเชิงพรรณนา เช่น ISO-8859-3 (ละติน-3), ISO- 8859-6 (ละติน/อารบิก). เป็นชุดใหญ่ของ ASCII ซึ่งหมายความว่า 128 ค่าแรกในการเข้ารหัสจะเหมือนกับ ASCII อย่างไรก็ตาม มันคือ 8 บิต และอนุญาตให้มีอักขระได้ 256 ตัว ดังนั้นมันจึงต่อยอดจากที่นั่นและมีอาร์เรย์ของอักขระที่กว้างกว่ามาก โดยการเข้ารหัสเฉพาะแต่ละรายการจะเน้นที่ชุดเกณฑ์ที่แตกต่างกัน Latin-1 รวมตัวอักษรและสัญลักษณ์ที่มีการเน้นเสียงไว้มากมาย แต่ต่อมาถูกแทนที่ด้วยชุดที่แก้ไขใหม่ที่เรียกว่า Latin-9 ซึ่งรวมถึงร่ายมนตร์ที่อัปเดตแล้ว เช่น สัญลักษณ์ยูโร


(ข้อความที่ตัดตอนมาจากสคริปต์ทิเบต Unicode v4 จาก unicode.org)
- Unicode – มาตรฐานการเข้ารหัสนี้มีจุดมุ่งหมายเพื่อความเป็นสากล ปัจจุบันมีสคริปต์ 93 บทที่จัดเป็นหลายช่วงตึก และอีกหลายช่วงที่อยู่ในงาน Unicode ทำงานแตกต่างจากชุดอักขระอื่น ๆ แทนที่จะเข้ารหัสโดยตรงสำหรับสัญลักษณ์ แต่ละค่าจะถูกนำไปยัง "จุดโค้ด" ต่อไป ค่าเหล่านี้เป็นค่าเลขฐานสิบหกที่สอดคล้องกับอักขระ แต่ตัวร่ายมนตร์เองถูกจัดเตรียมไว้ต่างหากโดยโปรแกรม เช่น เว็บเบราว์เซอร์ของคุณ จุดรหัสเหล่านี้มักแสดงดังนี้: U+0040 (ซึ่งแปลว่า '@') การเข้ารหัสเฉพาะภายใต้มาตรฐาน Unicode คือ UTF-8 และ UTF-16 UTF-8 พยายามที่จะอนุญาตให้มีความเข้ากันได้สูงสุดกับ ASCII เป็นแบบ 8 บิต แต่อนุญาตให้ใช้อักขระทั้งหมดผ่านกลไกการแทนที่และค่าหลายคู่ต่ออักขระ UTF-16 ขจัดความเข้ากันได้ของ ASCII ที่สมบูรณ์แบบสำหรับความเข้ากันได้แบบ 16 บิตที่สมบูรณ์ยิ่งขึ้นกับมาตรฐาน
- ISO-10646 – นี่ไม่ใช่การเข้ารหัสจริงๆ เป็นเพียงชุดอักขระของ Unicode ที่ได้รับมาตรฐาน ISO ส่วนใหญ่สำคัญเพราะเป็นละครอักขระที่ใช้โดย HTML ฟังก์ชันขั้นสูงบางอย่างที่มีให้โดย Unicode ที่อนุญาตให้มีการจัดเรียงและการเขียนสคริปต์จากขวาไปซ้ายควบคู่จากซ้ายไปขวาหายไป ยังคงใช้งานได้ดีบนอินเทอร์เน็ตเนื่องจากอนุญาตให้ใช้สคริปต์ที่หลากหลายและช่วยให้เบราว์เซอร์ตีความร่ายมนตร์ ทำให้การแปลเป็นภาษาท้องถิ่นค่อนข้างง่ายขึ้น
ฉันควรใช้การเข้ารหัสแบบใด
ASCII ใช้ได้กับผู้พูดภาษาอังกฤษส่วนใหญ่ แต่ไม่มากสำหรับอย่างอื่น บ่อยครั้งที่คุณจะเห็น ISO-8859-1 ซึ่งใช้ได้กับภาษายุโรปตะวันตกส่วนใหญ่ ISO-8859 เวอร์ชันอื่นๆ ใช้ได้กับอักษรซิริลลิก อาหรับ กรีก หรือสคริปต์เฉพาะอื่นๆ อย่างไรก็ตาม หากคุณต้องการแสดงสคริปต์หลายตัวในเอกสารเดียวกันหรือในหน้าเว็บเดียวกัน UTF-8 จะช่วยให้เข้ากันได้ดียิ่งขึ้น นอกจากนี้ยังใช้งานได้ดีมากสำหรับผู้ที่ใช้เครื่องหมายวรรคตอน สัญลักษณ์ทางคณิตศาสตร์ หรืออักขระที่ไม่เกี่ยวข้อง เช่น สี่เหลี่ยมและช่องทำเครื่องหมาย

(หลายภาษาในเอกสารเดียว ภาพหน้าจอของ gujaratsamachar.com)
มีข้อบกพร่องในแต่ละชุดอย่างไรก็ตาม ASCII มีเครื่องหมายวรรคตอนจำกัด ดังนั้นจึงใช้งานไม่ได้อย่างเหลือเชื่อสำหรับการแก้ไขการพิมพ์ที่ถูกต้อง เคยพิมพ์คัดลอก/วางจาก Word เพียงเพื่อให้มีการผสมผสานร่ายมนตร์แปลก ๆ หรือไม่? นั่นเป็นข้อเสียเปรียบของ ISO-8859 หรืออย่างถูกต้องกว่านั้นคือความสามารถในการทำงานร่วมกันกับโค้ดเพจเฉพาะของระบบปฏิบัติการ (เรากำลังดูที่คุณ Microsoft!) ข้อเสียเปรียบหลักของ UTF-8 คือการขาดการสนับสนุนที่เหมาะสมในการแก้ไขและเผยแพร่แอปพลิเคชัน ปัญหาอีกประการหนึ่งคือเบราว์เซอร์มักไม่ตีความและแสดงเฉพาะเครื่องหมายลำดับไบต์ของอักขระที่เข้ารหัส UTF-8 ส่งผลให้มีการแสดงร่ายมนตร์ที่ไม่ต้องการ และแน่นอน การประกาศการเข้ารหัสและใช้อักขระจากอีกตัวหนึ่งโดยไม่ประกาศ/อ้างอิงอย่างถูกต้องบนหน้าเว็บ ทำให้ยากสำหรับเบราว์เซอร์ในการแสดงผลอย่างถูกต้อง และสำหรับเครื่องมือค้นหาจะจัดทำดัชนีอย่างเหมาะสม
สำหรับเอกสาร ต้นฉบับ และอื่นๆ คุณสามารถใช้ทุกอย่างที่จำเป็นเพื่อให้งานสำเร็จลุล่วง เท่าที่เว็บดำเนินไป ดูเหมือนว่าคนส่วนใหญ่เห็นด้วยกับการใช้เวอร์ชัน UTF-8 ที่ไม่ใช้เครื่องหมายลำดับไบต์ แต่ก็ไม่เป็นเอกฉันท์ทั้งหมด อย่างที่คุณเห็น การเข้ารหัสอักขระแต่ละตัวมีการใช้งาน บริบท จุดแข็งและจุดอ่อนของตัวเอง ในฐานะผู้ใช้ปลายทาง คุณอาจจะไม่ต้องจัดการกับเรื่องนี้ แต่ตอนนี้ คุณสามารถก้าวไปข้างหน้าอีกขั้นได้หากต้องการ