
Quali sono le codifiche dei caratteri come ANSI e Unicode e in che cosa differiscono?
Pubblicato: 2022-01-29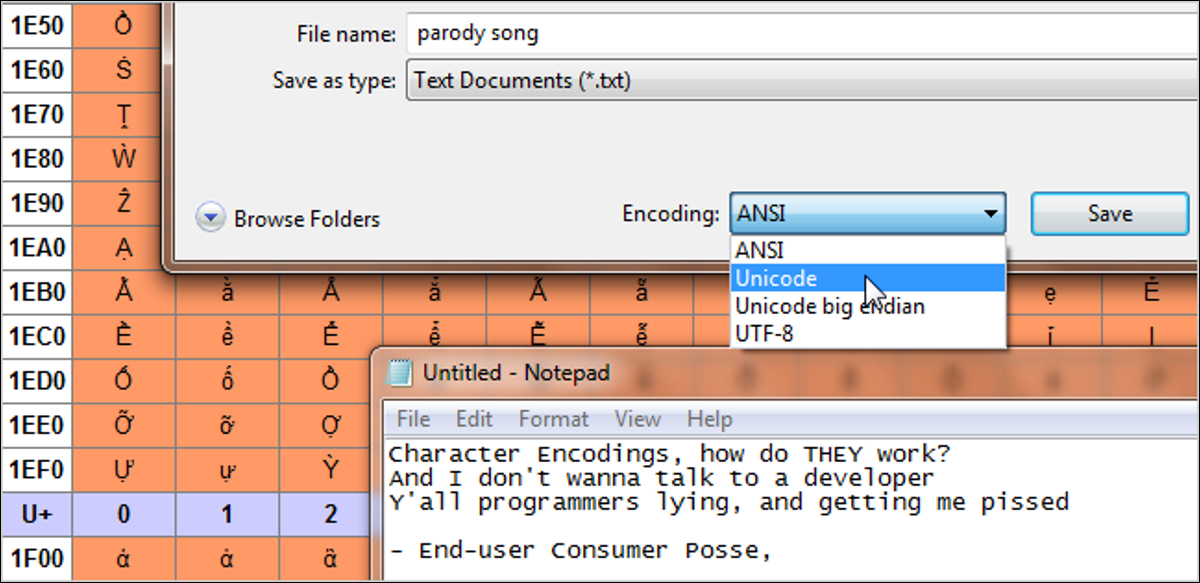
ASCII, UTF-8, ISO-8859... Potresti aver visto questi strani moniker fluttuare in giro, ma cosa significano in realtà? Continua a leggere mentre spieghiamo cos'è la codifica dei caratteri e come questi acronimi si riferiscono al testo normale che vediamo sullo schermo.
Mattoni fondamentali
Quando si parla di lingua scritta, si parla di lettere come elementi costitutivi delle parole, che poi costruiscono frasi, paragrafi e così via. Le lettere sono simboli che rappresentano i suoni. Quando parli di lingua, stai parlando di gruppi di suoni che si uniscono per formare una sorta di significato. Ogni sistema linguistico ha un insieme complesso di regole e definizioni che governano quei significati. Se hai una parola, è inutile a meno che tu non sappia da quale lingua proviene e la usi con altri che parlano quella lingua.
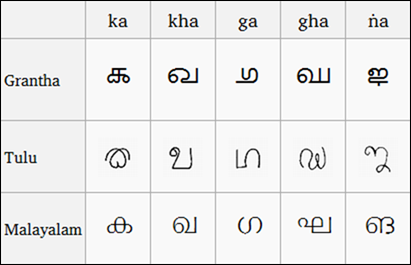
(Confronto tra gli script Grantha, Tulu e Malayalam, immagine da Wikipedia)
Nel mondo dei computer, usiamo il termine "personaggio". Un carattere è una sorta di concetto astratto, definito da parametri specifici, ma è l'unità fondamentale del significato. La "A" latina non è la stessa di una "alfa" greca o di un "alif" arabo perché hanno contesti diversi – provengono da lingue diverse e hanno pronunce leggermente diverse – quindi possiamo dire che sono caratteri diversi. La rappresentazione visiva di un personaggio è chiamata "glifo" e diversi insiemi di glifi sono chiamati font. Gruppi di personaggi appartengono a un "set" o a un "repertorio".
Quando scrivi un paragrafo e cambi il carattere, non stai cambiando i valori fonetici delle lettere, stai cambiando il loro aspetto. È solo cosmetico (ma non irrilevante!). Alcune lingue, come l'antico egiziano e il cinese, hanno ideogrammi; questi rappresentano idee intere anziché suoni e le loro pronunce possono variare nel tempo e nella distanza. Se sostituisci un carattere con un altro, stai sostituendo un'idea. È più che cambiare le lettere, sta cambiando un ideogramma.
Codifica dei caratteri

(Immagine da Wikipedia)
Quando si digita qualcosa sulla tastiera o si carica un file, come fa il computer a sapere cosa visualizzare? Ecco a cosa serve la codifica dei caratteri. Il testo sul tuo computer non è in realtà lettere, è una serie di valori alfanumerici accoppiati. La codifica dei caratteri agisce come una chiave per cui i valori corrispondono a quali caratteri, proprio come l'ortografia determina quali suoni corrispondono a quali lettere. Il codice Morse è una sorta di codifica dei caratteri. Spiega come i gruppi di unità lunghe e corte come i segnali acustici rappresentano i caratteri. Nel codice Morse, i caratteri sono solo lettere inglesi, numeri e punti. Esistono molte codifiche dei caratteri del computer che si traducono in lettere, numeri, segni di accento, segni di punteggiatura, simboli internazionali e così via.
Spesso su questo argomento viene utilizzato anche il termine “codepage”. Sono essenzialmente codifiche di caratteri utilizzate da aziende specifiche, spesso con lievi modifiche. Ad esempio, la tabella codici di Windows 1252 (precedentemente nota come ANSI 1252) è una forma modificata dell'ISO-8859-1. Sono utilizzati principalmente come sistema interno per fare riferimento a codifiche di caratteri standard e modificate specifiche degli stessi sistemi. All'inizio, la codifica dei caratteri non era così importante perché i computer non comunicavano tra loro. Con Internet che sta diventando famoso e il networking è un evento comune, è diventato un aspetto sempre più importante della nostra vita quotidiana senza che ce ne rendiamo nemmeno conto.
Molti tipi diversi

(Immagine di Sarah Sosiak)
Ci sono molte diverse codifiche di caratteri là fuori e ci sono molte ragioni per questo. La codifica dei caratteri che scegli di utilizzare dipende dalle tue esigenze. Se comunichi in russo, ha senso usare una codifica dei caratteri che supporti bene il cirillico. Se comunichi in coreano, allora vorrai qualcosa che rappresenti bene Hangul e Hanja. Se sei un matematico, allora vuoi qualcosa che abbia tutti i simboli scientifici e matematici rappresentati bene, così come i glifi greci e latini. Se sei un burlone, forse trarresti vantaggio da un testo capovolto. E, se vuoi che tutti questi tipi di documenti siano visualizzati da una determinata persona, vuoi una codifica abbastanza comune e facilmente accessibile.
Diamo un'occhiata ad alcuni di quelli più comuni.

(Estratto della tabella ASCII, Immagine da asciitable.com)
- ASCII - L'American Standard Code for Information Interchange è una delle codifiche di caratteri più vecchie. È stato originariamente concepito sulla base di codici telegrafici e si è evoluto nel tempo per includere più simboli e alcuni caratteri di controllo non stampati ormai obsoleti. Probabilmente è il più semplice che puoi ottenere in termini di sistemi moderni, poiché è limitato all'alfabeto latino senza caratteri accentati. La sua codifica a 7 bit consente solo 128 caratteri, motivo per cui ci sono diverse varianti non ufficiali in uso in tutto il mondo.
- ISO-8859 – Il gruppo di codifiche dei caratteri più utilizzato dall'Organizzazione internazionale per la standardizzazione è il numero 8859. Ogni codifica specifica è designata da un numero, spesso preceduto da un moniker descrittivo, ad esempio ISO-8859-3 (Latin-3), ISO- 8859-6 (latino/arabo). È un superset di ASCII, il che significa che i primi 128 valori nella codifica sono gli stessi di ASCII. È a 8 bit, tuttavia, e consente 256 caratteri, quindi parte da lì e include una gamma di caratteri molto più ampia, con ciascuna codifica specifica incentrata su un diverso insieme di criteri. Latin-1 includeva un mucchio di lettere e simboli accentati, ma è stato successivamente sostituito con un set rivisto chiamato Latin-9 che include glifi aggiornati come il simbolo dell'euro.


(Estratto di scrittura tibetana, Unicode v4, da unicode.org)
- Unicode : questo standard di codifica mira all'universalità. Attualmente comprende 93 script organizzati in diversi blocchi, con molti altri in lavorazione. Unicode funziona in modo diverso rispetto ad altri set di caratteri in quanto invece di codificare direttamente un glifo, ogni valore viene indirizzato ulteriormente a un "punto di codice". Questi sono valori esadecimali che corrispondono ai caratteri ma i glifi stessi sono forniti in modo distaccato dal programma, come il tuo browser web. Questi punti di codice sono comunemente rappresentati come segue: U+0040 (che si traduce in '@'). Codifiche specifiche secondo lo standard Unicode sono UTF-8 e UTF-16. UTF-8 tenta di consentire la massima compatibilità con ASCII. È a 8 bit, ma consente tutti i caratteri tramite un meccanismo di sostituzione e più coppie di valori per carattere. UTF-16 elimina la perfetta compatibilità ASCII per una più completa compatibilità a 16 bit con lo standard.
- ISO-10646 – Questa non è una codifica vera e propria, solo un set di caratteri Unicode che è stato standardizzato dall'ISO. È soprattutto importante perché è il repertorio di caratteri utilizzato da HTML. Mancano alcune delle funzioni più avanzate fornite da Unicode che consentono le regole di confronto e lo scripting da destra a sinistra insieme a quello da sinistra a destra. Tuttavia, funziona molto bene per l'uso su Internet in quanto consente l'utilizzo di un'ampia varietà di script e consente al browser di interpretare i glifi. Questo rende la localizzazione un po' più semplice.
Quale codifica dovrei usare?
Bene, ASCII funziona per la maggior parte degli anglofoni, ma non per molto altro. Più spesso vedrai ISO-8859-1, che funziona per la maggior parte delle lingue dell'Europa occidentale. Le altre versioni di ISO-8859 funzionano per caratteri cirillici, arabi, greci o altri caratteri specifici. Tuttavia, se desideri visualizzare più script nello stesso documento o sulla stessa pagina Web, UTF-8 consente una compatibilità molto migliore. Funziona molto bene anche per le persone che usano la punteggiatura corretta, i simboli matematici o i caratteri improvvisati, come quadrati e caselle di controllo.

(Più lingue in un documento, Screenshot di gujaratsamachar.com)
Tuttavia, ci sono degli svantaggi in ogni set. ASCII è limitato nei segni di punteggiatura, quindi non funziona incredibilmente bene per le modifiche tipograficamente corrette. Hai mai digitato copia/incolla da Word solo per avere una strana combinazione di glifi? Questo è lo svantaggio di ISO-8859, o più correttamente, la sua presunta interoperabilità con le codepage specifiche del sistema operativo (stiamo guardando a TE, Microsoft!). Il principale svantaggio di UTF-8 è la mancanza di un adeguato supporto nelle applicazioni di editing e pubblicazione. Un altro problema è che i browser spesso non interpretano e visualizzano semplicemente il segno dell'ordine dei byte di un carattere codificato UTF-8. Ciò comporta la visualizzazione di glifi indesiderati. E, naturalmente, dichiarare una codifica e utilizzare i caratteri di un'altra senza dichiararli/riferirsi correttamente su una pagina Web rende difficile per i browser renderli correttamente e per i motori di ricerca indicizzarli in modo appropriato.
Per i tuoi documenti, manoscritti e così via, puoi usare tutto ciò di cui hai bisogno per portare a termine il lavoro. Per quanto riguarda il Web, tuttavia, sembra che la maggior parte delle persone sia d'accordo sull'utilizzo di una versione UTF-8 che non utilizza un byte order mark, ma non è del tutto unanime. Come puoi vedere, ogni codifica dei caratteri ha il proprio uso, contesto e punti di forza e di debolezza. Come utente finale, probabilmente non dovrai occuparti di questo, ma ora puoi fare un ulteriore passo avanti se lo desideri.