
ANSI ve Unicode Gibi Karakter Kodlamaları Nelerdir ve Nasıl Farklılaşırlar?
Yayınlanan: 2022-01-29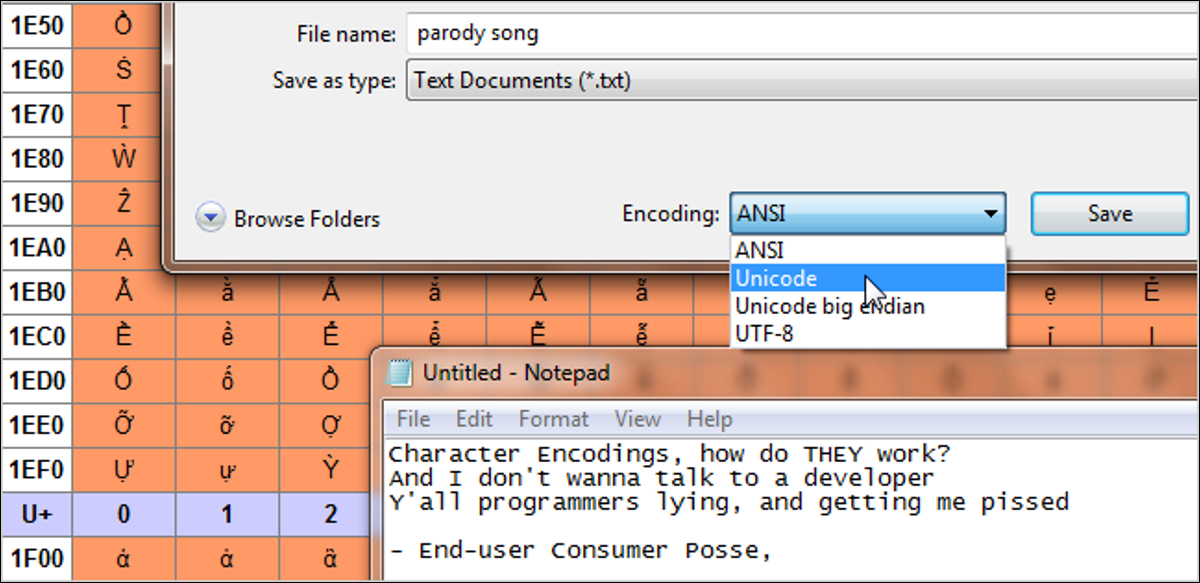
ASCII, UTF-8, ISO-8859… Etrafta dolaşan bu garip takma adları görmüş olabilirsiniz, ancak bunlar aslında ne anlama geliyor? Karakter kodlamasının ne olduğunu ve bu kısaltmaların ekranda gördüğümüz düz metinle nasıl ilişkili olduğunu açıklarken okumaya devam edin.
Temel Yapı Taşları
Yazılı dil hakkında konuştuğumuzda, kelimelerin yapı taşları olan ve daha sonra cümleler, paragraflar vb. oluşturan harfler hakkında konuşuruz. Harfler sesleri temsil eden sembollerdir. Dil hakkında konuştuğunuzda, bir tür anlam oluşturmak için bir araya gelen ses gruplarından bahsediyorsunuz. Her dil sistemi, bu anlamları yöneten karmaşık bir kurallar ve tanımlar dizisine sahiptir. Eğer bir sözünüz varsa, hangi dilden geldiğini bilmedikçe ve o dili konuşan başkalarıyla birlikte kullanmadıkça faydasız.
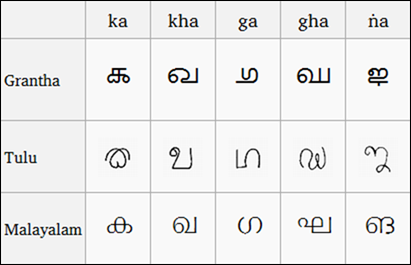
(Grantha, Tulu ve Malayalam komut dosyalarının karşılaştırılması, Wikipedia'dan Resim)
Bilgisayar dünyasında "karakter" terimini kullanıyoruz. Karakter, belirli parametrelerle tanımlanan bir tür soyut kavramdır, ancak temel anlam birimidir. Latince 'A', Yunanca 'alfa' veya Arapça 'alif' ile aynı değildir çünkü farklı bağlamlara sahiptirler – farklı dillerdendirler ve biraz farklı telaffuzları vardır – bu nedenle farklı karakterler olduklarını söyleyebiliriz. Bir karakterin görsel temsiline "glif" denir ve farklı glif kümelerine yazı tipi adı verilir. Karakter grupları bir "küme" veya "repertuara" aittir.
Bir paragraf yazıp yazı tipini değiştirdiğinizde, harflerin fonetik değerlerini değil, görünüşlerini değiştirmiş olursunuz. Bu sadece kozmetik (ama önemsiz değil!). Eski Mısır ve Çince gibi bazı dillerin ideogramları vardır; bunlar sesler yerine bütün fikirleri temsil eder ve telaffuzları zaman ve mesafeye göre değişebilir. Bir karakteri diğerinin yerine koyarsanız, bir fikri değiştirmiş olursunuz. Bu sadece harfleri değiştirmekten daha fazlasıdır, bir ideogramı değiştirmektir.
Karakter kodlaması

(Wikipedia'dan resim)
Klavyede bir şey yazdığınızda veya bir dosya yüklediğinizde, bilgisayar neyi göstereceğini nasıl biliyor? Karakter kodlaması bunun içindir. Bilgisayarınızdaki metin aslında harfler değildir, bir dizi eşleştirilmiş alfasayısal değerdir. Karakter kodlaması, imlanın hangi seslerin hangi harflere karşılık geldiğini nasıl belirlediğine benzer şekilde, hangi değerlerin hangi karakterlere karşılık geldiği konusunda bir anahtar görevi görür. Mors kodu, bir tür karakter kodlamasıdır. Bip sesleri gibi uzun ve kısa birim gruplarının karakterleri nasıl temsil ettiğini açıklar. Mors alfabesinde karakterler yalnızca İngilizce harfler, sayılar ve noktadır. Harflere, sayılara, vurgu işaretlerine, noktalama işaretlerine, uluslararası simgelere vb. dönüşen birçok bilgisayar karakter kodlaması vardır.
Bu konuda sıklıkla “kod sayfaları” terimi de kullanılmaktadır. Bunlar, genellikle küçük değişikliklerle belirli şirketler tarafından kullanılan karakter kodlamalarıdır. Örneğin, Windows 1252 kod sayfası (eski adıyla ANSI 1252), ISO-8859-1'in değiştirilmiş bir biçimidir. Çoğunlukla aynı sistemlere özgü standart ve değiştirilmiş karakter kodlamalarına atıfta bulunmak için dahili bir sistem olarak kullanılırlar. Başlangıçta, bilgisayarlar birbirleriyle iletişim kuramadığı için karakter kodlaması o kadar önemli değildi. İnternetin ön plana çıkması ve ağ oluşturmanın yaygın bir olay olmasıyla birlikte, biz farkına bile varmadan günlük hayatımızda giderek daha önemli hale geldi.
Birçok Farklı Tür

(Sarah Sosiak'ın fotoğrafı)
Dışarıda pek çok farklı karakter kodlaması var ve bunun birçok nedeni var. Hangi karakter kodlamasını kullanmayı seçtiğiniz, ihtiyaçlarınıza bağlıdır. Rusça iletişim kurarsanız, Kiril'i iyi destekleyen bir karakter kodlaması kullanmak mantıklıdır. Korece iletişim kurarsanız, Hangul ve Hanja'yı iyi temsil eden bir şey isteyeceksiniz. Bir matematikçiyseniz, Yunan ve Latin gliflerinin yanı sıra iyi temsil edilen tüm bilimsel ve matematiksel sembollere sahip bir şey istiyorsunuz. Şakacıysanız, ters çevrilmiş metinlerden faydalanabilirsiniz. Ve tüm bu tür belgelerin herhangi bir kişi tarafından görüntülenmesini istiyorsanız, oldukça yaygın ve kolay erişilebilir bir kodlama istiyorsunuz.
Daha yaygın olanlardan bazılarına bir göz atalım.

(ASCII tablosundan alıntı, asciitable.com'dan görüntü)
- ASCII – Bilgi Değişimi için Amerikan Standart Kodu, eski karakter kodlamalarından biridir. Başlangıçta telgraf kodlarına dayalı olarak tasarlandı ve zamanla daha fazla sembol ve artık modası geçmiş bazı yazdırılmamış kontrol karakterlerini içerecek şekilde gelişti. Aksanlı karakterler içermeyen Latin alfabesiyle sınırlı olduğundan, modern sistemler açısından alabileceğiniz kadar basit olabilir. 7 bit kodlaması yalnızca 128 karaktere izin verir, bu nedenle dünya çapında kullanımda olan birkaç resmi olmayan varyant vardır.
- ISO-8859 – Uluslararası Standardizasyon Örgütü'nün en yaygın olarak kullanılan karakter kodlamaları grubu 8859'dur. Her özel kodlama, genellikle tanımlayıcı bir takma adla öne çıkan bir sayı ile belirtilir, örneğin ISO-8859-3 (Latin-3), ISO- 8859-6 (Latin/Arapça). Bu, ASCII'nin bir üst kümesidir, yani kodlamadaki ilk 128 değer ASCII ile aynıdır. Bununla birlikte, 8 bittir ve 256 karaktere izin verir, bu nedenle oradan gelişir ve çok daha geniş bir karakter dizisini içerir, her bir özel kodlama farklı bir ölçüt kümesine odaklanır. Latin-1 bir grup aksanlı harf ve sembol içeriyordu, ancak daha sonra yerini Euro sembolü gibi güncellenmiş glifleri içeren Latin-9 adlı revize edilmiş bir set aldı.


(Unicode.org'dan Tibet alfabesi, Unicode v4, alıntı)
- Unicode – Bu kodlama standardı evrenselliği amaçlar. Şu anda birkaç blok halinde düzenlenmiş 93 komut dosyası içeriyor ve daha birçoğu da çalışıyor. Unicode, bir glifi doğrudan kodlamak yerine, her değerin bir "kod noktasına" daha fazla yönlendirildiği için diğer karakter kümelerinden farklı çalışır. Bunlar, karakterlere karşılık gelen onaltılık değerlerdir, ancak gliflerin kendileri, web tarayıcınız gibi program tarafından ayrılmış bir şekilde sağlanır. Bu kod noktaları genellikle şu şekilde gösterilir: U+0040 ('@' anlamına gelir). Unicode standardı kapsamındaki özel kodlamalar UTF-8 ve UTF-16'dır. UTF-8, ASCII ile maksimum uyumluluğa izin vermeye çalışır. 8 bittir, ancak bir ikame mekanizması ve karakter başına birden çok değer çifti aracılığıyla tüm karakterlere izin verir. UTF-16, standartla daha eksiksiz bir 16-bit uyumluluk için mükemmel ASCII uyumluluğunu ortadan kaldırır.
- ISO-10646 – Bu gerçek bir kodlama değildir, yalnızca ISO tarafından standartlaştırılmış bir Unicode karakter kümesidir. Çoğunlukla önemlidir, çünkü HTML tarafından kullanılan karakter repertuarıdır. Unicode tarafından sağlanan ve soldan sağa komut dosyası oluşturmanın yanı sıra sağdan sola harmanlamaya izin veren daha gelişmiş işlevlerden bazıları eksik. Yine de, çok çeşitli komut dosyalarının kullanımına izin verdiği ve tarayıcının glifleri yorumlamasına izin verdiği için internette kullanım için çok iyi çalışıyor. Bu, yerelleştirmeyi biraz daha kolaylaştırır.
Hangi Kodlamayı Kullanmalıyım?
Eh, ASCII çoğu İngilizce konuşan için işe yarar, ancak başka pek bir şey için değil. Daha sık olarak, çoğu Batı Avrupa dilinde çalışan ISO-8859-1'i göreceksiniz. ISO-8859'un diğer sürümleri Kiril, Arapça, Yunanca veya diğer belirli komut dosyaları için çalışır. Ancak, aynı belgede veya aynı web sayfasında birden fazla komut dosyası görüntülemek istiyorsanız, UTF-8 çok daha iyi uyumluluk sağlar. Ayrıca, uygun noktalama işaretleri, matematik sembolleri veya kareler ve onay kutuları gibi manşet dışı karakterler kullanan kişiler için gerçekten iyi çalışır.

(Bir belgede birden çok dil, gujaratsamachar.com'un Ekran Görüntüsü)
Bununla birlikte, her setin dezavantajları vardır. ASCII, noktalama işaretlerinde sınırlıdır, bu nedenle tipografik olarak doğru düzenlemeler için inanılmaz derecede iyi çalışmaz. Hiç garip bir glif kombinasyonuna sahip olmak için Word'den kopyala/yapıştır yazdınız mı? Bu, ISO-8859'un veya daha doğrusu, işletim sistemine özel kod sayfalarıyla varsayılan birlikte çalışabilirliğinin dezavantajıdır (Size bakıyoruz, Microsoft!). UTF-8'in en büyük dezavantajı, uygulamaları düzenleme ve yayınlama konusunda uygun desteğin olmamasıdır. Başka bir sorun da, tarayıcıların genellikle UTF-8 kodlu bir karakterin bayt sırası işaretini yorumlamaması ve görüntülemesidir. Bu, istenmeyen gliflerin görüntülenmesine neden olur. Ve elbette, bir kodlamayı bildirmek ve bir web sayfasında düzgün bir şekilde bildirmeden/referans vermeden diğerinden karakterleri kullanmak, tarayıcıların bunları doğru bir şekilde oluşturmasını ve arama motorlarının uygun şekilde dizine eklemesini zorlaştırır.
Kendi belgeleriniz, el yazmalarınız vb. için, işi halletmek için ihtiyacınız olan her şeyi kullanabilirsiniz. Web'e gelince, çoğu insanın bir bayt sipariş işareti kullanmayan bir UTF-8 sürümünü kullanma konusunda hemfikir olduğu görülüyor, ancak bu tamamen oybirliği değil. Gördüğünüz gibi, her karakter kodlamasının kendi kullanımı, bağlamı ve güçlü ve zayıf yönleri vardır. Bir son kullanıcı olarak, muhtemelen bununla uğraşmak zorunda kalmayacaksınız, ancak şimdi isterseniz fazladan bir adım atabilirsiniz.