
什麼是 ANSI 和 Unicode 等字符編碼,它們有何不同?
已發表: 2022-01-29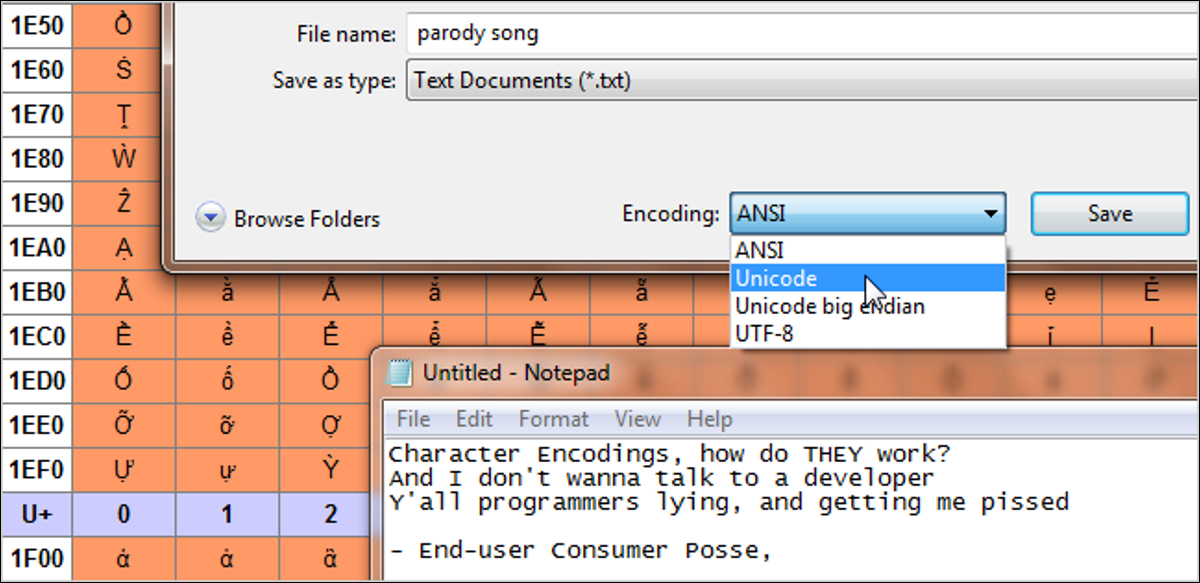
ASCII、UTF-8、ISO-8859……您可能已經看到了這些奇怪的名字,但它們的真正含義是什麼? 在我們解釋什麼是字符編碼以及這些首字母縮略詞與我們在屏幕上看到的純文本之間的關係時,請繼續閱讀。
基本構建塊
當我們談論書面語言時,我們談論的是字母是單詞的組成部分,然後構成句子、段落等。 字母是代表聲音的符號。 當您談論語言時,您是在談論組合在一起形成某種意義的聲音組。 每個語言系統都有一套複雜的規則和定義來管理這些含義。 如果你有一個詞,除非你知道它來自什麼語言並且你和其他說這種語言的人一起使用它,否則它是沒有用的。
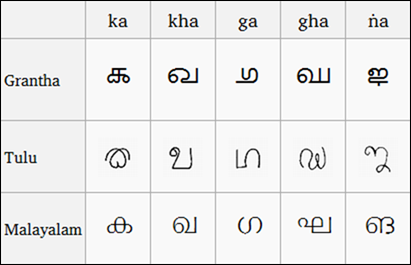
(Grantha、Tulu 和馬拉雅拉姆語腳本的比較,圖片來自維基百科)
在計算機世界中,我們使用術語“字符”。 字符是一種抽象概念,由特定參數定義,但它是意義的基本單位。 拉丁語“A”與希臘語“alpha”或阿拉伯語“alif”不同,因為它們有不同的上下文——它們來自不同的語言並且發音略有不同——所以我們可以說它們是不同的字符。 字符的視覺表示稱為“字形”,不同的字形集稱為字體。 字符組屬於“集合”或“曲目”。
當你輸入一個段落並改變字體時,你並沒有改變字母的音值,你改變了它們的外觀。 這只是化妝品(但並非不重要!)。 有些語言,如古埃及語和漢語,有表意文字; 這些代表完整的想法而不是聲音,並且它們的發音會隨著時間和距離而變化。 如果你用一個字符替換另一個字符,你就是在替換一個想法。 這不僅僅是改變字母,而是改變表意文字。
字符編碼

(圖片來自維基百科)
當您在鍵盤上鍵入內容或加載文件時,計算機如何知道要顯示什麼? 這就是字符編碼的用途。 您計算機上的文本實際上不是字母,而是一系列成對的字母數字值。 字符編碼充當其值對應於哪些字符的鍵,就像正字法如何指示哪些聲音對應於哪些字母一樣。 摩爾斯電碼是一種字符編碼。 它解釋了諸如嗶嗶聲之類的長短單位組如何表示字符。 在摩爾斯電碼中,字符只是英文字母、數字和句號。 有許多計算機字符編碼可以翻譯成字母、數字、重音符號、標點符號、國際符號等。
通常在這個主題上,也使用術語“代碼頁”。 它們本質上是特定公司使用的字符編碼,通常稍作修改。 例如,Windows 1252 代碼頁(以前稱為 ANSI 1252)是 ISO-8859-1 的修改形式。 它們主要用作內部系統來指代特定於相同系統的標準和修改的字符編碼。 早期,字符編碼並不那麼重要,因為計算機之間不能相互通信。 隨著互聯網的興起和網絡的普及,它在我們的日常生活中變得越來越重要,而我們甚至沒有意識到這一點。
許多不同的類型

(圖片來自莎拉索西亞克)
那裡有很多不同的字符編碼,這有很多原因。 您選擇使用哪種字符編碼取決於您的需求。 如果您使用俄語進行交流,那麼使用能夠很好地支持西里爾文的字符編碼是有意義的。 如果你用韓語交流,那麼你會想要能很好地代表韓文和漢字的東西。 如果您是一名數學家,那麼您需要能夠很好地表示所有科學和數學符號以及希臘語和拉丁語字形的東西。 如果你是個惡作劇者,也許你會從顛倒的文字中受益。 而且,如果您希望任何給定的人都可以查看所有這些類型的文檔,那麼您需要一種非常常見且易於訪問的編碼。
讓我們來看看一些比較常見的。


(ASCII 表摘錄,圖片來自 asciitable.com)
- ASCII – 美國信息交換標準代碼是較舊的字符編碼之一。 它最初是基於電報代碼設計的,並隨著時間的推移而演變為包含更多符號和一些現已過時的非印刷控製字符。 它可能與現代系統一樣基本,因為它僅限於沒有重音字符的拉丁字母。 它的 7 位編碼僅允許 128 個字符,這就是為什麼在世界各地使用了幾種非官方變體的原因。
- ISO-8859 – 國際標準化組織使用最廣泛的字符編碼組是數字 8859。每個特定的編碼都由一個數字指定,通常以一個描述性名稱作為前綴,例如 ISO-8859-3 (Latin-3)、ISO- 8859-6(拉丁文/阿拉伯文)。 它是 ASCII 的超集,這意味著編碼中的前 128 個值與 ASCII 相同。 然而,它是 8 位的,允許 256 個字符,因此它從那裡構建並包含更廣泛的字符數組,每個特定的編碼都側重於一組不同的標準。 Latin-1 包括一堆重音字母和符號,但後來被稱為 Latin-9 的修訂集取代,其中包括更新的字形,如歐元符號。

(摘自藏文,Unicode v4,來自 unicode.org)
- Unicode – 該編碼標準旨在實現普遍性。 它目前包括 93 個腳本,這些腳本被組織在幾個塊中,還有更多正在製作中。 Unicode 與其他字符集的工作方式不同,因為它不是直接對字形進行編碼,而是將每個值進一步定向到一個“代碼點”。 這些是對應於字符的十六進制值,但字形本身是由程序以分離的方式提供的,例如您的 Web 瀏覽器。 這些代碼點通常描述如下:U+0040(轉換為“@”)。 Unicode 標準下的特定編碼是 UTF-8 和 UTF-16。 UTF-8 試圖最大程度地兼容 ASCII。 它是 8 位的,但通過替換機制和每個字符的多對值允許所有字符。 UTF-16 拋棄了完美的 ASCII 兼容性,以實現與標準的更完整的 16 位兼容性。
- ISO-10646 – 這不是實際的編碼,只是 ISO 標準化的 Unicode 字符集。 這很重要,因為它是 HTML 使用的字符庫。 缺少 Unicode 提供的一些更高級的功能,這些功能允許整理和從右到左以及從左到右的腳本編寫。 儘管如此,它仍然非常適合在 Internet 上使用,因為它允許使用各種腳本並允許瀏覽器解釋字形。 這使得本地化稍微容易一些。
我應該使用什麼編碼?
好吧,ASCII 適用於大多數說英語的人,但不適用於其他很多。 您會經常看到適用於大多數西歐語言的 ISO-8859-1。 ISO-8859 的其他版本適用於西里爾文、阿拉伯文、希臘文或其他特定文字。 但是,如果您想在同一個文檔或同一個網頁上顯示多個腳本,UTF-8 可以提供更好的兼容性。 它也適用於使用正確標點符號、數學符號或即興字符(例如正方形和復選框)的人。

(一份文檔中的多種語言,gujaratsamachar.com 的屏幕截圖)
然而,每組都有缺點。 ASCII 的標點符號受到限制,因此對於印刷正確的編輯來說效果不佳。 曾經從 Word 中輸入複製/粘貼只是為了得到一些奇怪的字形組合? 這就是 ISO-8859 的缺點,或者更準確地說,它假定的與特定於操作系統的代碼頁的互操作性(我們正在尋找你,微軟!)。 UTF-8 的主要缺點是在編輯和發布應用程序中缺乏適當的支持。 另一個問題是瀏覽器通常不解釋,只顯示 UTF-8 編碼字符的字節順序標記。 這會導致顯示不需要的字形。 當然,聲明一種編碼並使用另一種編碼而不在網頁上正確聲明/引用它們會使瀏覽器難以正確呈現它們並且搜索引擎難以適當地索引它們。
對於您自己的文檔、手稿等,您可以使用完成工作所需的任何內容。 不過,就網絡而言,似乎大多數人都同意使用不使用字節順序標記的 UTF-8 版本,但這並不完全一致。 如您所見,每種字符編碼都有其自己的用途、上下文以及優缺點。 作為最終用戶,您可能不必處理這個問題,但如果您願意,現在您可以向前邁出額外的一步。